

图为我参观浙理宇树机器人实验室时所拍。也是人生第一次近距离接触机器人。
前言
最近我在使用 IsaacLab 框架部署 Unitree G1 强化学习项目(Unitree RL Lab)时,踩了不少坑。从环境配置、路径挂载,到显存爆炸,甚至还遭遇了更新 NVIDIA 驱动导致整个系统断网的“毁灭性”打击。经过几天的不懈折腾,总算是把这些问题一个个啃下来了。这篇文章就来系统地复盘一下整个调试与排坑的过程,希望能帮到遇到类似问题的同学少走弯路。
一、 训练与断点续传机制
在使用 rsl_rl 进行训练时,框架默认会根据一定的步数或代数(iteration)将模型的权重自动保存到指定的日志目录中(通常在 logs 文件夹下,按时间或环境后缀创建新目录)。
但如果训练因为意外原因中断,或者我们想基于某个较好的阶段性结果继续训练,该怎么做呢?我们可以通过添加 --resume 参数,配合指定的检查点来实现断点续传。
1. 确认上次训练的保存位置
首先检查你的项目目录下,一般会存在一个 logs 文件夹(比如 logs/rsl_rl/Unitree-G1-29dof-Velocity/2026-03-14_XXX/)。在里面你会发现类似于 model_XXXX.pt 的文件,数字最大的就是最后一次保存的检查点。
2. 继续训练的命令
运行训练脚本时添加 --resume 标志即可,框架会自动去最新的日志目录里找上一次最新的模型(检查点):
./unitree_rl_lab.sh -t --task Unitree-G1-29dof-Velocity --num_envs 2048 --resume
如果你有多个日志文件夹,且自动识别的不是你想用的那一个,你可以显式地指定 load_run 路径:
./unitree_rl_lab.sh -t --task Unitree-G1-29dof-Velocity --num_envs 2048 --resume --load_run "2026-03-14_XXX"
(其中的 "2026-03-14_XXX" 换成你对应 log 文件夹的具体名称即可)。
二、 项目部署与调试实录
在跑通训练之前,遇到了各式各样的环境与依赖报错。以下是整个过程的核心诊断与修复记录:
环境信息: Linux (Ubuntu), PyTorch, Isaac Sim/IsaacLab, Anaconda
1. 初始环境与挂载盘问题修复 (NTFS软链接损坏)
- 问题描述:在执行
unitree_rl_lab.sh时,提示找不到bash\r,且虚拟环境中的 Python 执行报错无法执行二进制文件:可执行文件格式错误。 - 诊断与解决:
- 首先使用
dos2unix去除了.sh脚本中的 Windows CRLF 换行符。 - 随后发现 Conda 虚拟环境安装在 NTFS 格式的外部挂载硬盘 (victory) 上,导致 Linux 的软链接(Symlink)全部损坏为 Windows 的快捷方式占位符。
- 修复:在
unitree_rl_lab.sh中注入了一个自定义函数_ut_resolve_python_exe()。该函数通过动态递归解析断裂的软链接符号,找到了真实存在的python3.11二进制文件,替换默认的python调用,成功唤起了 Python 解释器。
- 首先使用
2. IsaacLab 物理资产 (USD) 路径配置错误
- 问题描述:启动训练时报错
ValueError: No contact sensors added to the prim以及FileNotFoundError: USD file not found at path,找不到g1_29dof_rev_1_0.usd。 - 诊断与解决:
- 检查了位于
usd的文件确实存在。 - 修复:定位到 Python 配置文件
unitree.py,将其中的全局变量UNITREE_MODEL_DIR从错误的路径硬编码修复为实际存在的物理文件挂载路径"/media/robot/victory/AIGC/unitree_model"。
- 检查了位于
3. Git LFS 与 Conda 钩子权限冲突
- 问题描述:执行环境配置脚本时遇到
git lfs install Hook already exists: pre-push和activate.d/setenv.sh: Permission denied。 - 诊断与解决:
- 这是开发环境初始化常见的残留锁定现象。
- 修复:通过赋予
setenv.sh执行权限以及利用--force绕过 Git LFS hook 的冲突来完成配置。
4. GPU 显存限制 (6GB VRAM) 导致的核心崩溃
- 问题描述:使用指令开启训练后,很快弹出
torch.OutOfMemoryError: CUDA out of memory以及随后出现的RuntimeError: normal expects all elements of std >= 0.0。 - 诊断与解决:
- 默认的 4096 个并行环境 (
num_envs) 超出了 6GB GPU 显存的承载能力。显存不足导致张量分配失败或计算截断,进而导致 PPO 策略分布的方差 (std) 生成 NaN,从而让模型立刻崩溃爆炸。 - 修复:将训练时的环境数量降级,手动添加指令参数
--num_envs 2048,成功将显存占用控制在安全水位内。此外这也明确了按Ctrl+C随时中断不会破坏已经保存下来的.pt训练权重。
- 默认的 4096 个并行环境 (
5. IsaacLab 版本演进导致的代码不兼容与模块迁移
- 问题描述:在使用测试模式
play.py时出现ModuleNotFoundError: No module named 'isaaclab.utils.pretrained_checkpoint'。 - 诊断与解决:
- 由于底层 IsaacLab 包发生了版本结构变更,部分工具模块从基础库移动到了 RL 专用库中。
- 修复:修改项目脚本
play.py的第 59 行,将原先的from isaaclab.utils.pretrained_checkpoint ...修改为from isaaclab_rl.utils.pretrained_checkpoint ...。
6. GUI 渲染器崩溃(无头模式绕过)
- 问题描述:运行
play推理模式时,报错rtx driver verification failed和NVIDIA graphics driver is unsupported(系统当前为 535.32,最低要求 535.129),弹出界面一片空白。后来在试图通过图形界面更新驱动时又各种受限。 - 诊断与解决:
- 这是由于显卡驱动过旧,无法启动 Omniverse RTX 渲染器。
- 绕过手段:通过在测试命令后添加
--headless参数 (./unitree_rl_lab.sh -p --task Unitree-G1-29dof-Velocity --headless),彻底跳过图形学渲染。此时终端输出了完整的Actor MLP和Critic MLP网络结构参数与环境观测集,这标志着基于断点权重的强化学习模型已经在后台成功加载并运转。
三、 惊险时刻:Ubuntu 更新 NVIDIA 驱动断网修复战
既然说到了驱动过旧的问题,于是我尝试直接升级显卡驱动。但在 Ubuntu 系统中更新 NVIDIA 显卡驱动后重启,系统右上角的网络图标彻底消失,无法连接有线或无线网络。检查 systemctl status NetworkManager 显示服务依然在运行,但 lspci 或 ip link 发现底层物理网卡却集体“失联”。
问题根源
Ubuntu 在通过包管理器更新 NVIDIA 驱动时,顺带触发了 Linux 内核(Kernel)的升级。但在升级过程中,新内核未能成功包含并安装 linux-modules-extra 软件包。这个包包含了大多数主流网卡和 Wi-Fi 硬件的底层驱动,系统进入新内核后就像变成了瞎子,根本认不得网卡。
🛠️ Cross-Kernel(跨内核)修复法
思路的核心是:“借用旧内核的网络,给新内核抓药。”
第一步:退回旧内核恢复网络
- 重启电脑,在开机出现主板 Logo 后迅速狂按
Esc或长按Shift进入 GRUB 引导菜单。 - 选择
Advanced options for Ubuntu(Ubuntu 高级选项)。 - 选择第二项或第三项(即上一个版本的旧内核,非 recovery mode)启动系统。
- 进入桌面后,由于旧内核拥有完整的网卡驱动,网络连接将会自动恢复。
第二步:锁定“肇事”的新内核版本
在拥有网络的旧内核下打开终端,排查系统中最新的缺驱动的内核版本号:
dpkg -l | grep linux-image- | awk '{print $2}'
(注:当时查出缺失驱动的新内核版本为
6.8.0-106-generic)
第三步:跨内核补全驱动依赖
利用开好的网络,直接为残缺的新内核定向安装网卡驱动包(extra)和内核头文件(headers):
sudo apt install linux-modules-extra-6.8.0-106-generic linux-headers-6.8.0-106-generic
第四步:重新编译驱动并刷新引导
确保新内核挂载好网卡驱动,并让显卡驱动与新内核完成绑定:
# 触发 DKMS 重新编译(如有预编译包则会秒过)
sudo dkms autoinstall -k 6.8.0-106-generic
# 将修好的驱动配置打包进内核镜像
sudo update-initramfs -u -k 6.8.0-106-generic
# 刷新开机启动项
sudo update-grub
第五步:验证与收尾
执行 reboot 正常重启电脑,默认进入最新的 6.8.0-106-generic 内核。
- 此时网络图标重新出现,网络连接恢复正常。
- 终端运行
nvidia-smi成功输出显卡面板,证明新内核下网卡与 NVIDIA 驱动已完美共存。
至此,驱动更新与网络问题彻底解决。我们终于可以去掉 --headless 无头参数,正常唤起 Isaac Sim 的渲染界面。以下是在本地环境中成功运行并渲染出 Unitree G1 强化学习模型的演示画面:
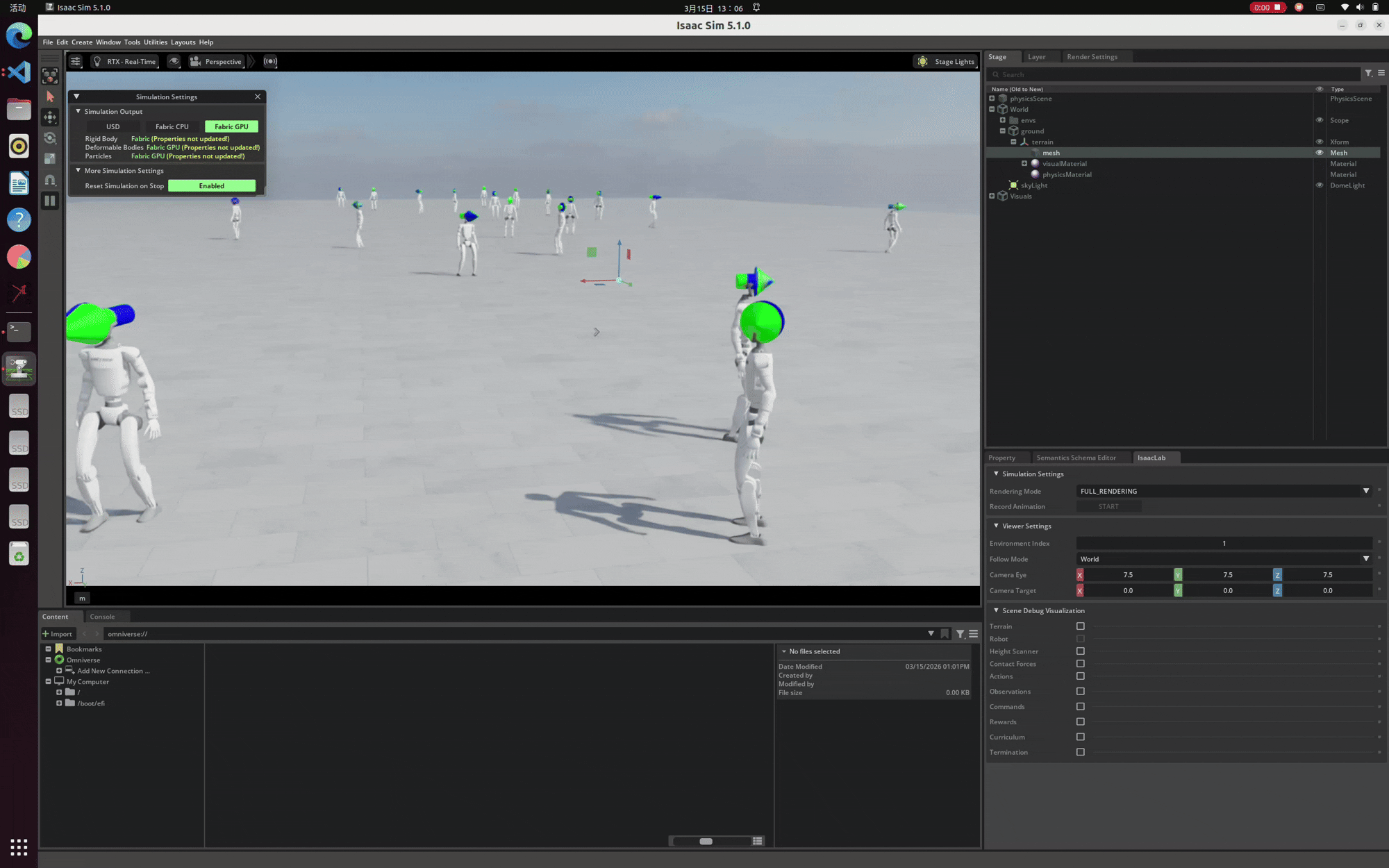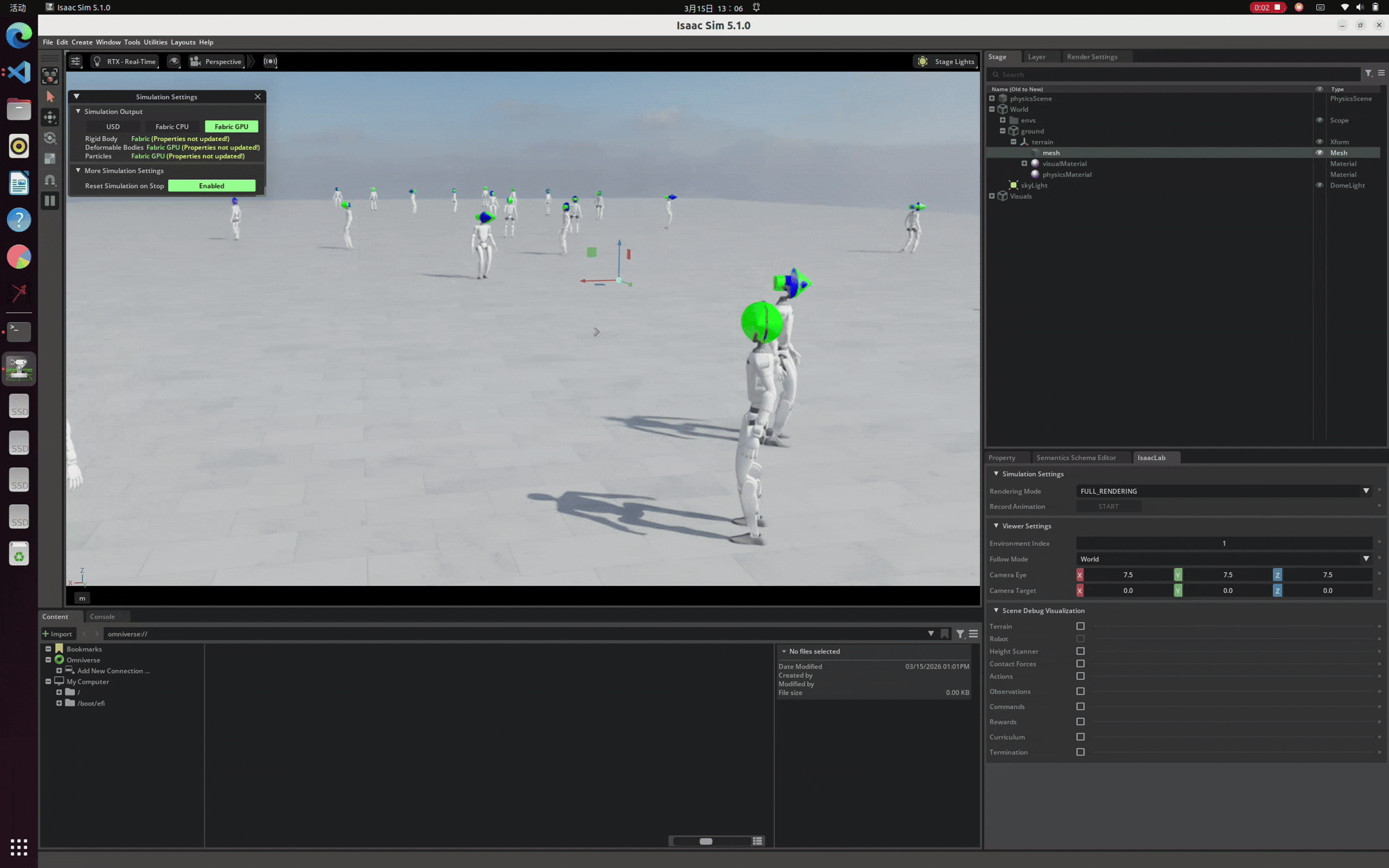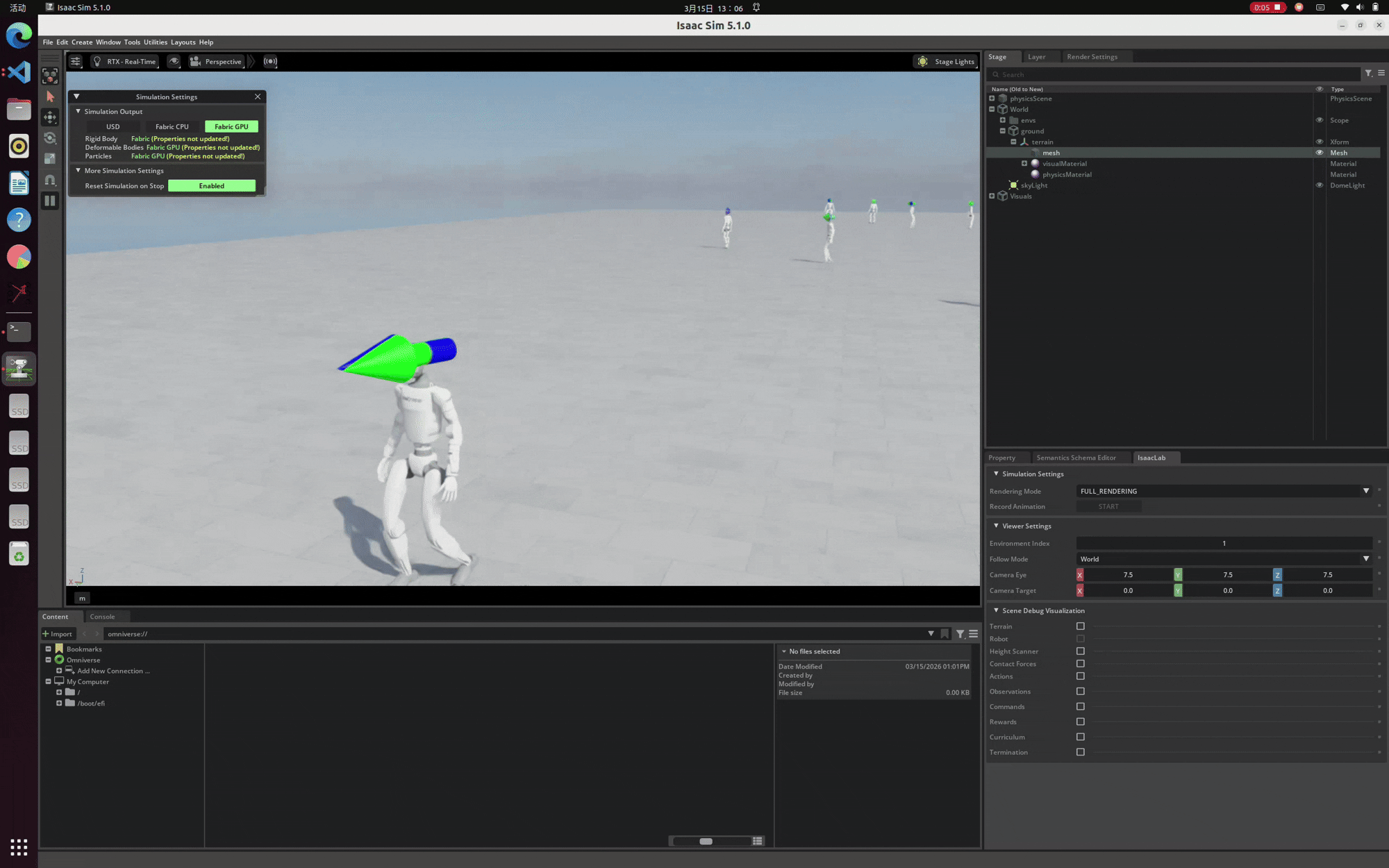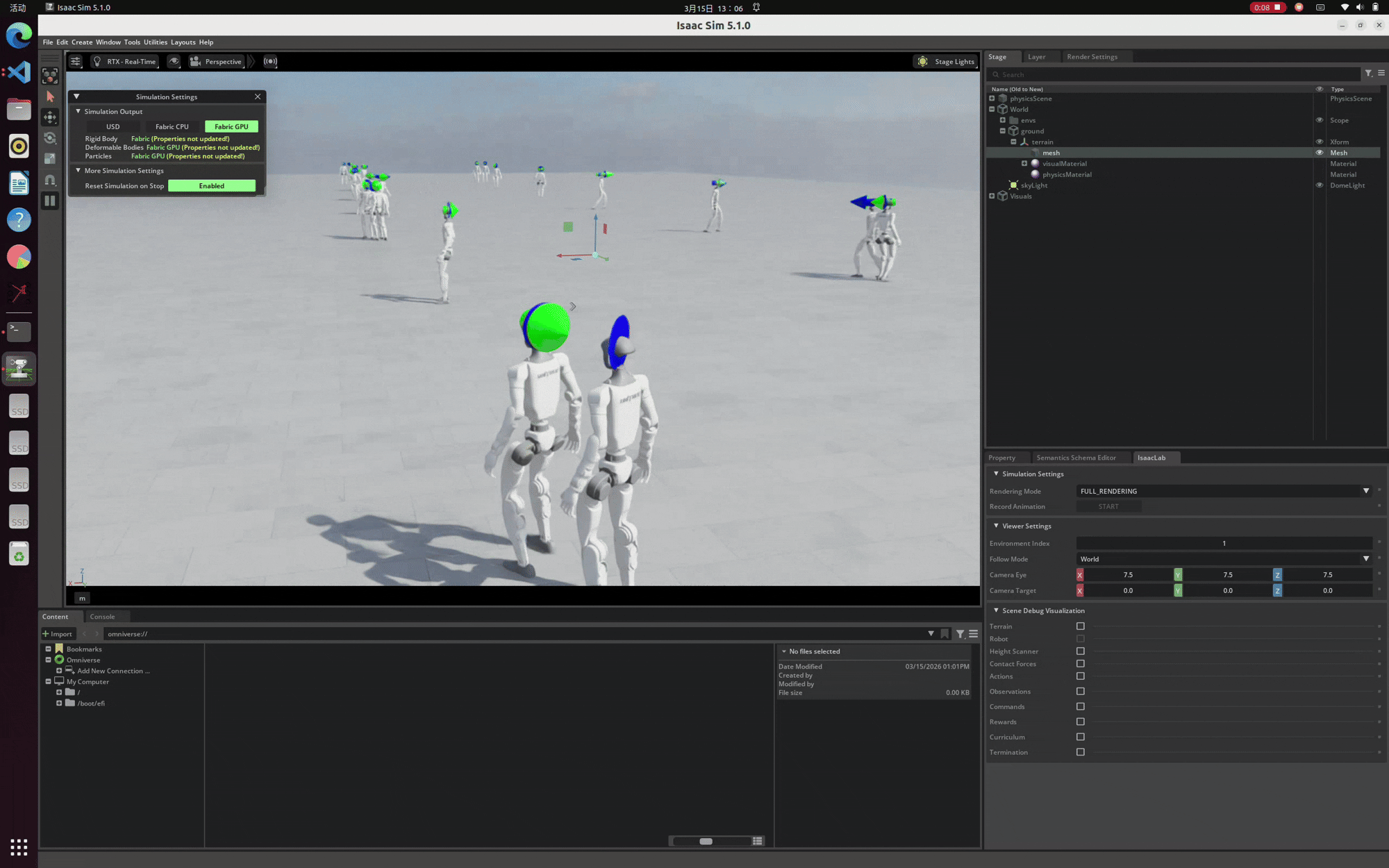
经历重重排坑后,最终在本地成功渲染出 Unitree G1 模型的效果演示。
感想
经过这一系列对于文件系统、代码路径硬编码、显存调度限制以及系统内核底层依赖的排查试错,我不仅成功把 Unitree-G1 强化学习环境搬到了自己设备上跑通,还意外地把 Ubuntu 断网老生常谈的“内核驱动依赖失联”难题给跨内核修复了。
在这个摸雷排坑的过程中我深刻意识到,一旦摸清底层原理并且真正化解后,增加的经验值是非常扎实的。这也让我对具身智能的算力环境和工程部署能力有了更直观的全貌认知,希望这些踩坑记录能给正在同个环境里奋战的朋友们提供点参考和启示!